Energieeffiziente Steuerung von Kältemaschinen durch KI
Prinzipien des maschinellen Lernens in der Kältetechnik
 Bild: Trevisto AG
Bild: Trevisto AG
 Bild: Trevisto AG
Bild: Trevisto AG
 Bild: Trevisto AG
Bild: Trevisto AG
 Bild: Trevisto AG
Bild: Trevisto AG
 Bild: Trevisto AG
Bild: Trevisto AG
 Bild: Trevisto AG
Bild: Trevisto AG
 Bild: Trevisto AG
Bild: Trevisto AG
 Bild: Trevisto AG
Bild: Trevisto AG
 Bild: Trevisto AG
Bild: Trevisto AG
 Tabelle 1
Tabelle 1
 Tabelle 2
Tabelle 2
Die Kältetechnik, die etwa 15 % des elektrischen Endenergieverbrauchs in Deutschland ausmacht [35], birgt ein erhebliches Energieeffizienzpotenzial und kann maßgeblich dazu beitragen, die Klimaschutzziele zu erreichen [36]. Kernziel des Verbundvorhaben „GOKAS – Gesamtsystemoptimierung von kältetechnischen Anlagensystemen für Energiewende und Klimaschutz“ war deshalb die Erforschung und Entwicklung von Methoden eines energetisch optimierten Betriebs von Kälteanlagen bei smarter Einbindung in andere Energiesysteme, wobei die Optimierung multivariabel gestaltet wurde. Zur Erreichung dieses Kernziels wurden innovative digitale Technologien wie z. B. Methoden aus den Bereichen Data Science und Computational Intelligence speziell für deren Einsatz für Optimierung, Monitoring und Automatisierung von Kälteanlagen erforscht.
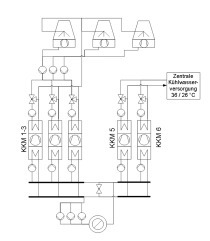
Das untersuchte System ist ein industrielles Kälteanlagensystems, s. Bild 1, im Produktionsprozess von Verpackungsmaterialien. Das System umfasst zwei indirekt betriebenen Kältemaschinen für Prozesskälte, Klimakälte und Maschinenkälte zur Herstellung von Folienverpackungen. Die Kältemaschine 1 (KM1) stellt die Klimakälte bereit, hier liegt der Bereich für die Kaltwassertemperatur zwischen 10 °C und 16 °C. Die Prozesskälte wird durch die Kältemaschine 2 (KM2) bereitgestellt, hier liegt der Arbeitsbereich zwischen 3 °C und 9 °C. Bei beiden Systemen sind Kaltwasserspeicher zwischen Kältemaschine und Verbraucher vorhanden. Die Rückkühlung der Kältemaschinen erfolgt über Rückkühlwerke und Kühltürme.
Da in diesem Anwendungsfall die Optimierung der Energieeffizienz anhand eines produktiv laufenden Systems betrachtet wird, ist ein Ansatz mittels definierter Bilanzräumen [37] sinnvoll, um auch eine Vergleichbarkeit der Kennzahlen zu erreichen. Ein Bilanzraum ist ein Bereich, innerhalb dessen Energie- und Stoffströme für die Beurteilung von Kennzahlen für Energieeffizienz erfasst, bilanziert und ausgewertet werden. Dabei sind hierarchisch gegliederte Bilanzräume, s. Bild 1, Tabelle 1, definiert.
Der Total Coefficient of Performance (TCOP) [37] ist eine Kennzahl, die die Energieeffizienz als Quotient aus eingesetzter Energie und der abgegebenen Kälteleistung beschreibt. Das konkrete Ziel des Anwendungsfalls bestand in der Optimierung des TCOP für die Kältemaschine KM2 im Bilanzraum I. Durch die Optimierung sollen Steuerungsvorschläge generiert werden, die Energieeinsparungen ermöglichen und damit die Betriebseffizienz der industriellen Kälteanlage verbessert.
Datengrundlage
Für die Analyse wurde ein mehrjähriger Datensatz aus der Gebäudeleittechnik (GLT) sowie dem Energiemanagementsystem „EnEffCo“ herangezogen. Die Daten lagen im CSV- und Excel-Format vor und wiesen eine zeitliche Auflösung von einer Minute auf. Der Datensatz aus beiden Quellen umfasst 368 Messgrößen (Sensoren) und beschreibt die thermodynamischen und betrieblichen Zustände des untersuchten Systems.
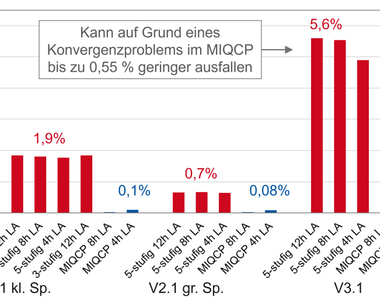
Mit den Messgrößen werden die Werte Kalt- und Kühlwassertemperaturen an Verdampfer und Verflüssiger, Kaltwasservolumenstrom sowie die Kaltwasserleistung der Verdampfer erfasst. Darüber hinaus enthalten die Daten Temperatur- und Druckwerte für Verdampfer und Verflüssiger sowie Kühl- und Kaltwassertemperaturen an Leitungen, Verbrauchern und die Außentemperatur. Zusätzlich sind Schaltbefehle bzw. die Anzahl aktiver Verdichter sowie Stellsignale für Kühlwasserpumpen, Kühlwasserventile, Ventilatoren, Besprühungspumpen, Verdichter und die elektrische Leistung der Kältemaschinen und Schaltschränke enthalten. Die GLT- und „EnEffCo“-Daten wurden in ein einheitliches Format gebracht und zu einem Datenpool zusammengefasst. Bei der Analyse der Daten wurden die relevanten Datenpunkte bzw. Messgrößen bestimmt, die einen Einfluss auf die Energieeffizienz haben. Einige Datenpunkte wurden durch verschiedene Sensoren mehrmals erfasst, hier wurden die Sensoren gewählt, die weniger Lücken / Ausfälle aufzeigten bzw. die korrekt kalibriert waren, siehe Bild 2.
Ferner wurden Ausreißer behandelt. Diese treten auf bei Anfahrphasen oder Ein- und Ausschaltvorgängen oder wenn die Kaltwasseraustrittstemperatur einen Grenzwert unterschreitet. Je nach Situation wurde die Ausreißer durch maximal bzw. minimal Werte ersetzt, bzw. ausgelassen. Neue Variablen wurde anhand vorhandener Datenpunkten berechnet und in den Datenpool integriert. Eine Analyse ergab, dass nur in wenigen Monaten Datenverfügbarkeit unter 80 % liegt.
Mittels Korrelationsanalysen wurden die Messgrößen ermittelt, welche für die Optimierungsaufgabe (Energieeinsparung bei möglichst gleichbleibender Kälteerzeugungsleistung) relevant sind.
Software
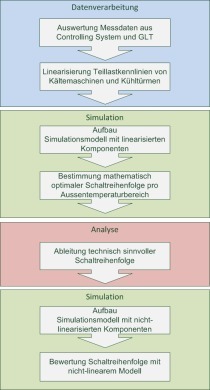
Die Architektur folgt einem vierstufigen Schichtenmodell aus Datenaufnahme, datenverarbeitender Aufbereitung, prognosebasierter Modellbildung sowie darauf aufbauender Optimierungs- und Entscheidungsfindung, siehe Bild 3.
Die erste Ebene (Ingestion) nimmt die ungefilterten Rohdaten auf und speichert die Daten persistent ab. Die Transformationsschicht bereinigt, resampled und reichert die Daten an. Hier wird auch die Datenqualität analysiert. In der Prognose-Ebene werden Zeitreihenmodelle bereitgestellt und die Güte der Modelle geprüft. In der Entscheidungs- und Optimierungsschicht werden auf der Basis der Modelprognose Steuer- und Regelstrategien abgeleitet.
Model-Based Reinforcement Learning
Die Optimierungsaufgabe ist ein typischer Ansatz für das Reinforcement Learning. Reinforcement Learning ist ein maschinelles Lernverfahren, bei dem ein Agent durch Interaktion mit seiner Umgebung lernt, indem er Aktionen ausführt und dafür durch eine Reward-Funktion (Belohnungsfunktion) für gute Aktionen Belohnungen und für schlechte Aktionen Bestrafungen erhält. Der Agent erlernt iterativ Handlungsregeln (Policy) um die erwartete kumulative Belohnung über die Zeit zu maximieren. Dieses Vorgehen ist als Markov-Entscheidungsprozess (MDP [38]) modelliert.
Zur Optimierung wurde ein MBRL-Ansatz [39–40] gewählt. Hierbei wird ein modellbasiertes Reinforcement Learning unter Verwendung eines datengetriebenen Prognosemodells durchgeführt. Bei der direkten Optimierung ist das Reinforcement Learning auf die in den Daten enthaltenen, empirisch beobachteten Zustandsübergänge beschränkt. Anzahl und Vielfalt der Lernsamples sind durch den Datenauszug festgelegt. Nicht beobachtete Systemzustände, geänderte Randbedingungen oder zukünftige Einflussgrößen können nicht erzeugt, bzw. für die Optimierung verwendet werden.
Um möglichst viele Systemzustände verwenden zu können und so ein gutes Optimierungsergebnis zu erhalten, ist der Datenbedarf sehr hoch. Dagegen hat der MBRL-Ansatz Vorteile, weil hier ein Prognosemodell als Simulationsumgebung vorbereitet wird, auf das das Optimierungsverfahren aufsetzt und somit auf synthetische Rollouts zugreifen kann. Mit dem Prognosemodell wird der Zustandsraum modellbasiert erweitert, Szenarien können variiert werden, und die Anzahl der verfügbaren Transitionen ist nicht mehr durch die historische Datenmenge limitiert. Durch Nutzung von Future Covariates [41] können zukünftige Informationen eingebunden werden. Zwar gibt es den zusätzlichen Aufwand für das Prognosemodell, jedoch kann das RL-Training schneller durchgeführt werden. Für den MBRL-Ansatz wurden folgendes Prognosemodell und Optimierungsverfahren implementiert.
Prognosemodell
Für die Modellierung der Zeitreihen wurde das Temporal Fusion Transformer (TFT)-Modell gewählt [42, 43], da es im Gegensatz zu klassischen Regressions- und LSTM-Ansätzen sowohl statische, vergangene und zukünftige Kovariaten integrieren kann, eine Vorhersage ganzer Zeitfenster (Multi-Horizon) statt nur einen Zeitpunkt ermöglicht. Mit einem Interpretierbarkeitsmechanismus (Attention und Variable Selection) ist eine transparente Modellanalyse möglich, man also kann ermitteln, welche Zeitpunkte in der Vergangenheit besonders relevant waren und welche Sensoren bzw. Einflussfaktoren am wichtigsten waren.
Es wurden drei Prognosemodelle mit unterschiedlichen Zeitfenstern (5 min, 10 min und 15 min) trainiert. Die Größe der Eingabe und Ausgabefenster waren jeweils identisch.
Die Auswertung der Metriken der drei Prognosemodelle zeigte, dass das Modell mit 5 min-Eingang/Ausgang am genauesten ist; mit längeren Prognosehorizonten (10/15 min) steigen die Abweichungen leicht an und die Vorhersagen werden systematisch etwas zu niedrig, siehe Tabelle 2.
Die Encoder Feature Importance bewertet, welche historischen Eingangsmerkmale (past covariates und vergangene Zielwerte) den größten Einfluss auf die Modellvorhersage haben. Hier zeigen die drei Prognosemodelle deutliche Differenzen – die Features mit dem größten Einfluss stehen ganz oben.
Insgesamt zeigt sich, dass die Prognosegüte deutlich vom gewählten Vorhersagehorizont abhängt: Das 5-Minuten-Modell liefert sowohl in den Fehlerkennzahlen als auch im Zeitreihenvergleich die stabilsten und realitätsnächsten Ergebnisse, während längere Horizonte zu erkennbar höheren Abweichungen und geglätteten bzw. zeitlich verschobenen Peaks führen. Die Unterschiede in der Encoder Feature Importance deuten zudem darauf hin, dass sich mit steigendem Horizont nicht nur die Genauigkeit, sondern auch die Relevanz einzelner Eingangssignale verändert, was auf eine vom Vorhersagehorizont abhängige Dynamik der Einflussfaktoren schließen lässt.
Optimierungsmodell
Für die Optimierung wurde der Algorithmus Trust Region Policy Optimization (TRPO) gewählt [45], da er im Vergleich zu klassischen Policy-Gradient-Verfahren durch die Begrenzung der Policy-Aktualisierung auf eine definierte Vertrauensregion eine deutlich höhere Trainingsstabilität bei kontinuierlichen und hochdimensionalen Aktionsräumen gewährleistet. Das bedeutet, dass TRPO eine starke Änderung der Policy (z. B. hoher Sprung eines Stellsignal von 60 % auf 95 %) durch den Agenten verhindert, weil Änderungen nur innerhalb einer Vertrauensregion (Trust Region) erlaubt sind. Das ist sehr wichtig bei realen Systemen, ein Agent darf nicht chaotisch handeln.
Prinzip des eingesetzten Deep-Reinforcement-Learning-Modells (DRL): Im Past Input Window werden historische Systeminformationen verarbeitet, das sind zeitlich zurückliegende Stellgrößen (Action Histories), Systemzustände (State-Features) und aus realen Betriebsdaten abgeleiteten Belohnungswerten (Observed Reward). Im Future Output Window werden zukünftige Systemzustände (Predicted State-Features) und Vorhersagen von Belohnungswerten für geplante Aktionen (Predicted Reward) integriert, die aus einem externen Prognose- bzw. Simulationsmodell stammen. Auf Basis dieser Eingangsgrößen generiert der RL-Agent eine Folge von Steueraktionen aus dem Action Space, welche auf die Umgebung wirken. Die resultierenden Systemrückmeldungen und Rewards fließen wiederum in den Lernprozess ein, sodass die zugrunde liegende Policy iterativ aktualisiert und hinsichtlich der angestrebten Optimierungsziele verbessert wird.
Es wurden auf der Basis der drei Prognosemodelle mit unterschiedlichen Zeitfenstern (5 min, 10 min und 15 min) verschiedene Optimierungen trainiert. Die Größe der Eingabe- und Ausgabefenster waren jeweils identisch mit denen der Prognosemodelle. Es wurden bezüglich der Inputdaten zwei Versionen getestet, die Realwerte der Kaltwasserleitung bzw. die Mittelwerte der Kaltwasserleitung. Bei allen Modellen wurde nur eine Aktion für das Ausgabefenster vorgegeben.
Bild 4 zeigt Evaluationsergebnisse und den Verlauf des Rewards an. Während das Model V4 5 Minuten deutliche Einsparung der elektrischen Leistung bei nahezu gleichbleibender Kälteleistung zeigt, weist das Model V3 15 Minuten sogar höhere Verbräuche der elektrischen Leistung und geringere Kälteleistung aus. Das Training wurde bei beiden über 10 Mio. Evaluationsteps durchgeführt. Das Model V4 5 Min. zeigt ein deutliches stabiles Plateau beim Reward an, wogegen das Model V3 15 Min. nach einiger Zeit das Niveau absinkt, was auf Overfitting, also Modeldrift hinweisen kann.
In Bild 5 sind die Veränderung der Kaltwasserleistung sowie elektrische Leistung und TCOP II durch die zwei exemplarische Optimierungsmodelle dargestellt. Man sieht, dass mit dem Model V4 5 Min. eine Verbesserung des TCOP um 11 % erreichbar ist, bei gleichbleibender Kaltwasserleistung und Ersparnis bei der elektrischen Leistung um 9 %. Hingegen erkennt man beim Model V3 15 Min. keine Verbesserung, der Verbrauch an elektrischer Energie geht leicht hoch und die Kaltwasserleistung wird nicht ganz gehalten.
Bild 6 zeigt einen Vergleich für drei Aktorkanäle zwischen realen Stellsignalen und den vom Optimierungsmodell vorhergesagten Stellsignalen. Das Modell erzeugt diskrete, sprunghafte Stellverläufe mit hoher Schalthäufigkeit und deutlich größeren Amplituden als im realen Betrieb. Aus regelungstechnischer Sicht ist dieses Verhalten kritisch, da es zu erhöhtem Verschleiß, instabilen Regelkreisen oder Sicherheitsabschaltungen führen kann, sofern keine Glättungs- oder Rampenbegrenzung implementiert wird. Eine mögliche Lösung besteht darin, Action-Smoothing zu verwenden (gleitende Mittelwerte, stärkere Rampenbegrenzung, Low-Pass-Filter) damit die Aktorbefehle nur innerhalb zulässiger Änderungsraten übergeben werden.
Schlussfolgerungen
Die vorliegende Arbeit demonstriert die erfolgreiche Anwendung eines zweistufigen KI-basierten Ansatzes zur energetischen Optimierung industrieller Kälteanlagen. Die Kombination aus Temporal Fusion Transformer für die Prognose und Deep Reinforcement Learning (TRPO) für die Optimierung ermöglichte eine Steigerung des TCOP um bis zu 11 % bei gleichzeitiger Reduktion der elektrischen Leistung um 9 %.
Die hohe Variabilität der generierten Stellsignale erfordert für den praktischen Einsatz die Implementierung von Glättungsmechanismen. Zukünftige Arbeiten sollten sich auf Action-Smoothing-Verfahren, die systematische Analyse der Aktor-Diskrepanzen, die Integration von Wetter- und Produktionsdaten sowie die Entwicklung von Transferlearning-Ansätzen für andere Anlagenkonfigurationen konzentrieren.
Zusätzliche Informationen
Ein ausführliches Literaturverzeichnis sowie ergänzende Bilder und Tabellen finden Sie online unter www.t1p.de/Klimke
Danksagung
Der Autor bedankt sich für die finanzielle Unterstützung durch das Bundesministerium für Wirtschaft und Klimaschutz auf der Grundlage eines Beschlusses des Deutschen Bundestages (Förderkennzeichen 03EN6003B) und bei Sebastian Haußer, HBI, für die fundierte fachliche Beratung im Laufe des Forschungsvorhabens sowie Almothana Alhaes für die hervorragende Entwicklungsarbeit.